Concepts
Datasets
A dataset in Airflow represents a logical collection of data. Upstream tasks that produce data can update datasets, and downstream DAGs that consume data can be scheduled based on dataset updates.
A dataset is defined by a Uniform Resource Identifier (URI):
from airflow import Dataset
example_dataset = Dataset("s3://dataset-bucket/example.csv")
The Universal Transfer Operator supports two Datasets specializations: Tables and Files, which enrich the original Airflow Datasets concept, for instance, by allowing uses to associate Airflow connections to them. Examples:
Tables
A Table Dataset refers to a table in a database or a data warehouse like Postgres, Snowflake, etc. that stores data. They can be used in Universal Transfer Operator as input dataset or output datasets. The supported databases can be found at Supported Databases.
There are two types of tables:
Persistent Table
These are tables that are of some importance to users. You can create these tables by passing in a
nameparameter while creating auniversal_transfer_operator.datasets.table.Tableobject.output_table = Table( name="uto_gs_to_bigquery_table", conn_id="google_cloud_default", metadata=Metadata(schema="astro"), )
Temporary Tables
The user can transfer data without giving the table name, and the universal transfer operator will make temporary tables that have unique names starting with
_tmp.There are two approaches to create temporary tables:
Explicit: instantiate a
universal_transfer_operator.datasets.table.Tableusing the argument temp=TrueImplicit: instantiate a
universal_transfer_operator.datasets.table.Tablewithout giving it a name, and without specifying the temp argumentoutput_table = Table( name="uto_gs_to_bigquery_table", conn_id="google_cloud_default", metadata=Metadata(schema="astro"), )
Metadata
Metadata gives additional information to access a SQL Table, if necessary and supported by the database used.
For example, a user can detail the Google Bigquery dataset and project for a table. Although these parameters can change name depending on the database, we have normalised the Metadata to offer a generic interface for them. The Universal transform operator names the top-level container of tables schema. The term schema is consistent with Snowflake and Postgres, for instance, but it maps to a BigQuery dataset. Users can also define databases within the Metadata, which are containers of schemas. This terminology is consistent with Snowflake and Postgres but maps to a Google project in the case Google Bigquery.
output_table = Table(
name="uto_gs_to_bigquery_table",
conn_id="google_cloud_default",
metadata=Metadata(schema="astro"),
)
Files
The File Dataset represents a file located on a storage mechanism such as S3, GCS, etc. This is a very common type of Dataset in data pipelines, often used as a source of data or as an output for analysis. The supported files can be found at Supported File Location.
There are two types of files:
File
These are individual files specified by the user. You can create these file by passing in a
pathparameter while creating auniversal_transfer_operator.datasets.base.Fileobject.source_dataset=File(path=f"{s3_bucket}/example_uto/", conn_id="aws_default"),
File pattern or folder location
The user can transfer data to and from folder or file pattern. We also resolve the Patterns in File path in file path based on the Supported File Location. For example:
input_file = File(path=f"{gcs_bucket}/example_uto/", conn_id="google_cloud_default")
Dataframe
A DataFrame is another type of Dataset that is becoming more popular in data pipelines. It used to be a temporary processing step within a single task, but now there are more demand and technologies for storing distributed data frames, such as Ray or Snowpark.
A DataFrame Dataset is still a reference object, but its URI may not be clear yet. This is because different frameworks have different ways of representing data frames, such as Spark, Pandas, or Snowpark.
API
An API Dataset refers to data that is obtained or published using a REST API from or to another system. Data pipelines often use this type of Dataset to get data from remote sources in JSON format.
Another type of API Dataset is used to send data to SaaS applications using a REST API. This is sometimes called “Reverse ETL” and it is an emerging operation.
How Universal Transfer Operator Works
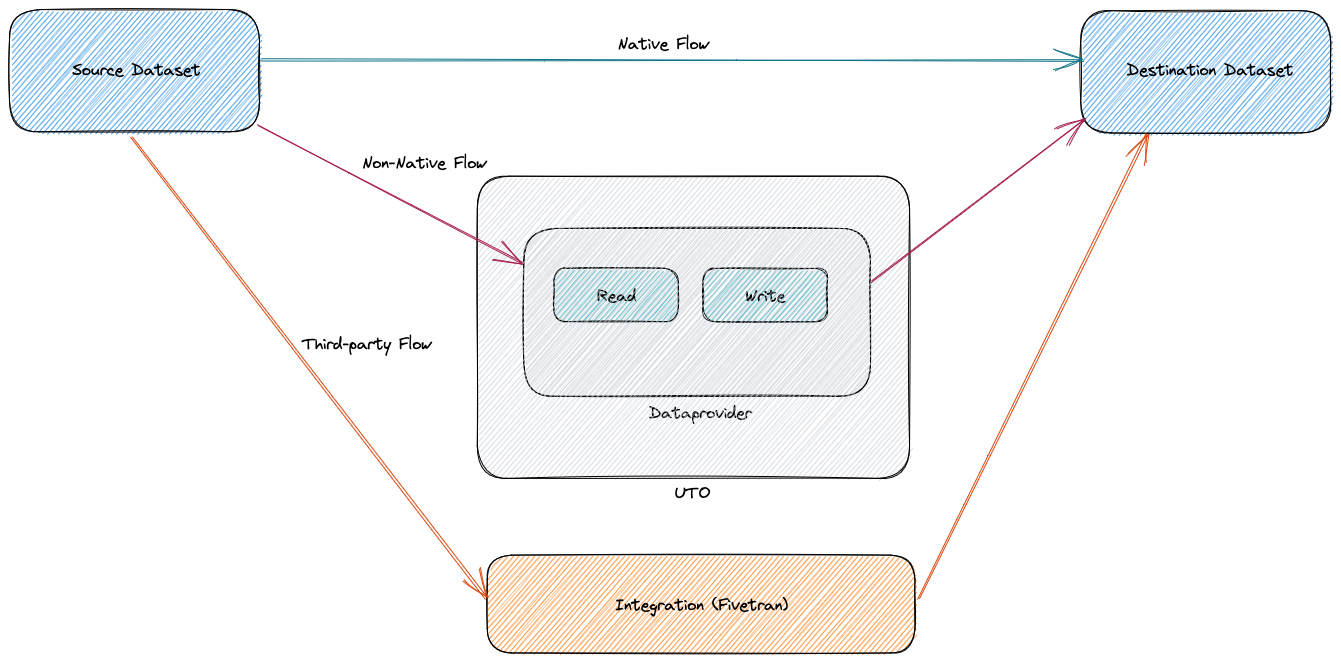
With universal transfer operator, users can perform data transfers using the following transfer modes:
NATIVE = "native"
NONNATIVE = "nonnative"
THIRDPARTY = "thirdparty"
Non-native transfer
When we load a data located in one dataset located in cloud to another dataset located in cloud, internally the steps involved are:
Steps:
Get the dataset data in chunks from dataset storage to the worker node.
Send data to the cloud dataset from the worker node.
This is the default way of transferring datasets. There are performance bottlenecks because of limitations of memory, processing power, and internet bandwidth of worker node.
Following is an example of non-native transfers between Google cloud storage and Sqlite:
transfer_non_native_gs_to_sqlite = UniversalTransferOperator(
task_id="transfer_non_native_gs_to_sqlite",
source_dataset=File(
path=f"{gcs_bucket}/example_uto/csv_files/", conn_id="google_cloud_default", filetype=FileType.CSV
),
destination_dataset=Table(name="uto_gs_to_sqlite_table", conn_id="sqlite_default"),
)
Improving bottlenecks by using native transfer
Some of the datasets on cloud like Bigquery and Snowflake support native transfer to ingest data from cloud storage directly. Using this we can ingest data much quicker and without any involvement of the worker node.
Steps:
Request destination dataset to ingest data from the file dataset.
Destination dataset request source dataset for data.
This is a faster way for datasets of larger size as there is only one network call involved and usually the bandwidth between vendors is high. Also, there is no requirement for memory/processing power of the worker node, since data never gets on the node. There is significant performance improvement due to native transfers.
Note
Native implementation is in progress and will be added in upcoming releases.
Transfer using third-party tool
The universal transfer operator can work smoothly with other platforms like FiveTran for data transfers.
Following are the supported third-party platforms:
Fivetran = "fivetran"
Here is an example of how to use Fivetran for transfers:
transfer_fivetran_with_connector_id = UniversalTransferOperator(
task_id="transfer_fivetran_with_connector_id",
source_dataset=File(path=f"{s3_bucket}/uto/", conn_id="aws_default"),
destination_dataset=Table(name="fivetran_test", conn_id="snowflake_default"),
transfer_mode=TransferMode.THIRDPARTY,
transfer_params=FiveTranOptions(conn_id="fivetran_default", connector_id="filing_muppet"),
)
Patterns in File path
We also resolve the patterns in file path based on the Supported File Location
Local - Resolves
File.pathusing the glob standard library (https://docs.python.org/3/library/glob.html)S3 - Resolves
File.pathusing AWS S3 prefix rules (https://docs.aws.amazon.com/AmazonS3/latest/userguide/using-prefixes.html)GCS - Resolves
File.pathusing Google Cloud Storage (GCS) wildcard rules (https://cloud.google.com/storage/docs/gsutil/addlhelp/WildcardNames)